Transkription, Übersetzung und Text-to-Speech mit Voice-Cloning
Wichtigsten Punkte auf einen Blick
- KI-gestütze Überwindung von Sprachbarrieren
- Transkription aus beliebiger Sprache
- Übersetzung in beliebige Sprache duch LLM
- Alternativ Verwendung des LLMs um Fragen zu beantworten, anstatt nur zu übersetzen
- Vorlesen des übersetzten Texts durch Text-to-Speech-System
- Optionales Voice-Cloning für Vorlesen mit eigener Stimme
Kurzbeschreibung
Sprachbarrieren sorgen sowohl im beruflichen als auch im alltäglichen Umfeld zunehmend für Herausforderungen. Große Sprachmodelle (LLMs) haben bereits viel dazu beigetragen, multilinguale Kommunikation zu ermöglichen, sind jedoch in der Regel noch auf rein textuelle Modalitäten beschränkt.
In letzter Zeit wird daher im Bereich KI viel zur Verarbeitung von gesprochener Sprache geforscht. Transkription funktioniert bereits seit längerem auf fast menschlichem Niveau in einer Vielzahl von Sprachen und auch Text-to-Speech-Systeme werden immer verlässlicher. Moderne Embedding-basierte KI-Modelle können selbst Voice-Cloning anhand von Beispielaufnahmen von weniger als einer Minute realisieren.
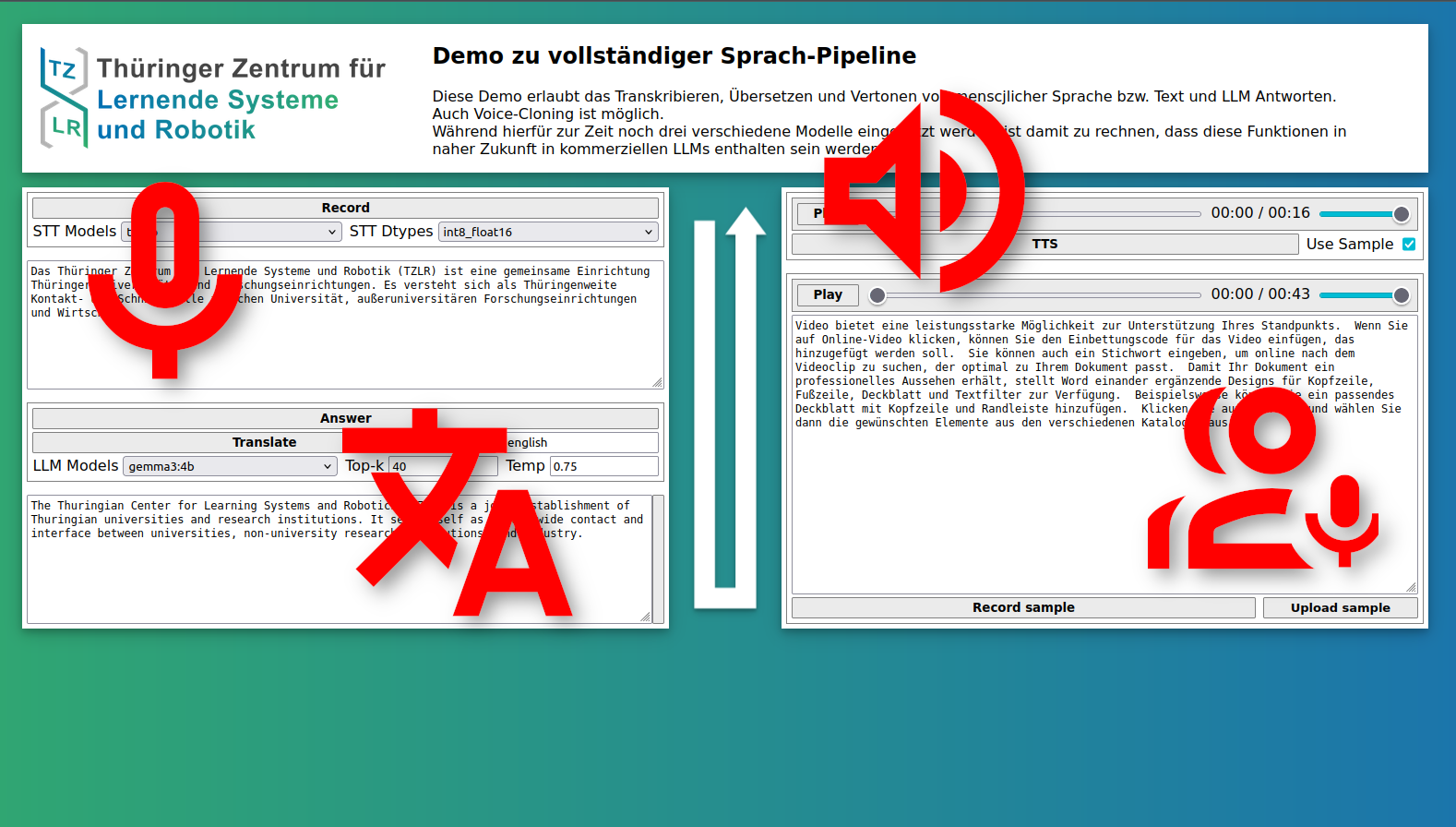
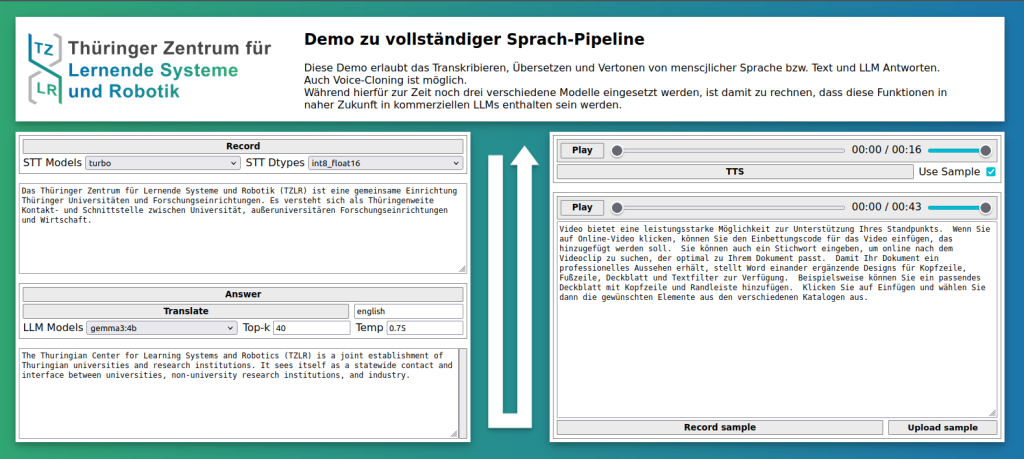
Der Demonstrator zeigt eine vollständige KI-basierte Sprach-Pipeline: Transkription, Übersetzung und Text-to-Speech mit optionalem Voice-Cloning in einer Vielzahl von Sprachen, u.a. Deutsch, Englisch oder Chinesisch.
Da hierfür drei verschiedene KI-Modelle zum Einsatz kommen, ist der Ansatz zur Zeit noch sehr ressourcenaufwändig. Zuhnemend werden allerdings monolithische Ansätze erfoscht, die alle drei Funktionen in einem einzigen großen Sprachmodell enthalten haben. Es ist zu erwarten, dass diese Funktionalität in der nahen Zukunft in den Modellen bzw. Apps der großen LLM-Anbieter enthalten sein wird.
Transfer und Nachnutzbarkeit
Sprachbarrieren können in zahlreichen Umgebungen durch die Pipeline von Transkription, Übersetzung und Text-to-Speech überwunden werden.
Genutzte Hardware
- PC mit mächtiger NVIDIA Grafikkarte (mindestens 12GB VRAM)