Optical Character Recognition (OCR) in Dokumenten mit Handschrift
Wichtigsten Punkte auf einen Blick
- Herkömmliche OCR-Systeme können gedruckten Text auf Bildern erkennen, eignen sich im Allgemeinen aber nicht, um handschriftlichen Text zu erfassen
- Multimodale Sprachmodelle (LLMs) können neben Text auch Bilder verarbeiten und dabei auch für das Erkennen von Text verwendet werden
- Mit ihrer Hilfe können physische Dokumente mit handschriftlichem Text transkribiert werden
Kurzbeschreibung
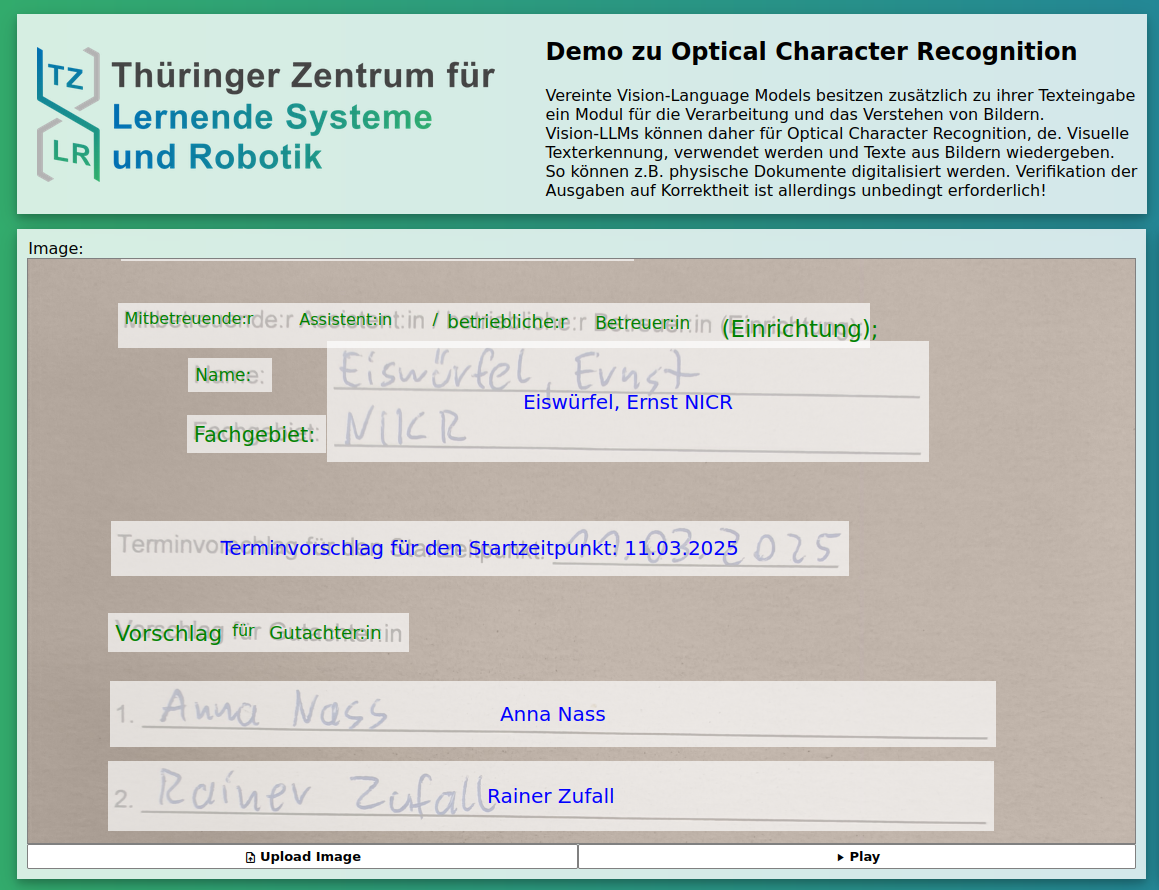
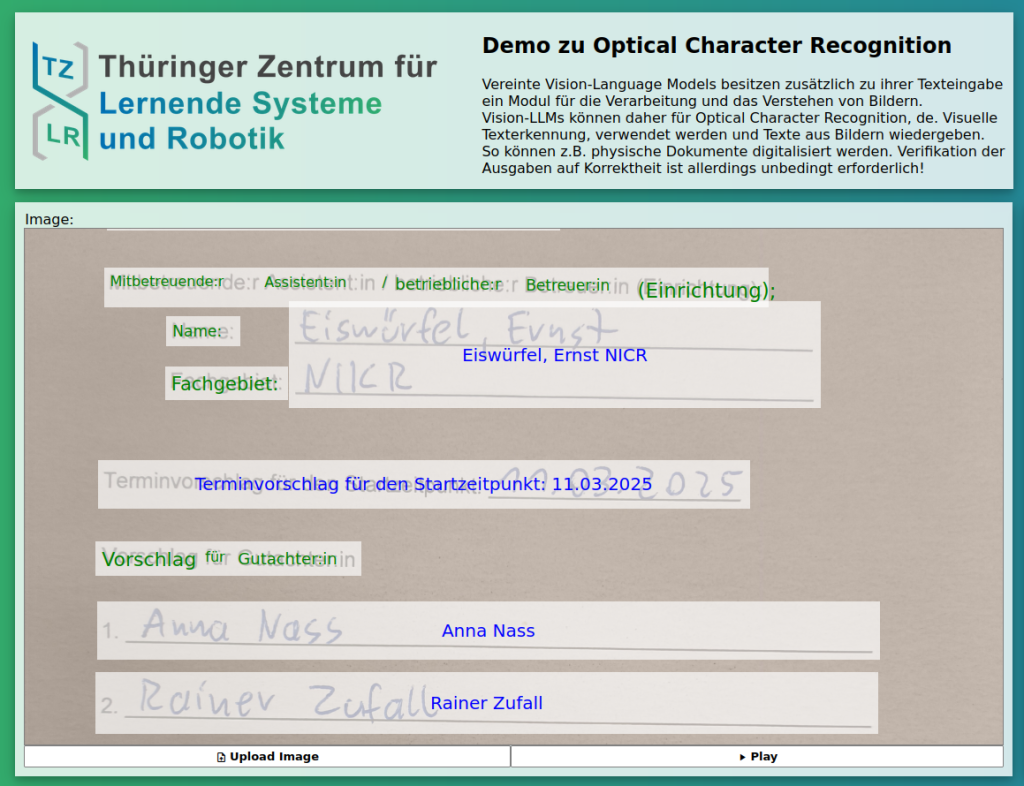
Systeme für Optical Character Recognition (OCR), de. Visuelle Texterkennung, sind bereits in vielen kommerziellen Programmen enthalten, z.B. in Adobe Acrobat und Google Lens.
Sie werden verwendet, um in Bildern Text zu erkennen und zu transkribieren. Dadurch können z.B. aus gescannten Dokumenten Text kopiert oder die Dokumente nach Schlagwörtern durchsucht werden.
Herkömmliche OCR-Systeme sind allerdings im Allgemeinen nicht in der Lage, handschriftlichen Text zu erkennen. An dieser Stelle können multimodale LLMs zum Einsatz kommen. Diese besitzen neben ihrer Texteingabe auch ein Modul für die Verarbeitung von Bildern. Sie können relativ verlässlich sowohl gedruckten, als auch handschriftlichen Text in Bildern erkennen und transkribieren.
Multimodale LLMs können alleinstehend eingesetzt oder mit traditionellen Bildverarbeitungsmethoden und herkömmlicher OCR-Software kombiniert werden, um Formularen und Dokumente mit handschriftliche Einträgen zu digitalisieren. Dabei ist die Verwendung von lokal gehosteten LLMs möglich, wenn private oder sensitive Dokumente verarbeitet werden.
Der Demonstrator besitzt keinen physischen Aufbau, d.h. es handelt sich um eine reine Software-Demo.
Transfer und Nachnutzbarkeit
Erlaubt das Transkribieren und Digitalisieren von physisch vorliegenden Formularen und Dokumenten, die neben gedrucktem Text auch handschriftliche Einträge enthalten.
Genutzte Hardware
- Laptop mit Grafikkarte:
- NVIDIA GeForce RTX 4080 mit 12GB RAM